
The Kubernetes Tax: How We Achieved Per-Microservice Blue-Green Deployments Using Kamal
When launching a new pilot project operating under tight initial resource constraints, your infrastructure decisions can bury the product before it ever reaches its first user.
Our challenge was classic: we needed a microservices architecture, an ultra-fast CI/CD pipeline, ephemeral testing environments for every Pull Request, and true Blue-Green (zero-downtime) deployments. The application was undergoing constant iterations, meaning our release windows couldn't afford maintenance gaps.
The standard industry choice? A managed Kubernetes cluster (like GKE or EKS). But after the initial math, reality hit hard: the fixed costs for the control plane and the operational complexity of maintaining such a stack represented a massive "complexity tax" that simply didn't align with our lean team and budget.
Enter Kamal 2. Promoted as a pragmatic alternative providing the simplicity of a distributed docker-compose, Kamal promised clean deployments directly onto bare VPS instances. However, moving from a monolith on a single machine to a distributed microservices architecture forced us to tackle an architectural barrier that the documentation often glosses over.
The Architectural Blindspot: Service Discovery Without CoreDNS
In a Kubernetes cluster, microservices communicate effortlessly. If the Core service needs to call the Search service, it simply hits http://search-service. K8s leverages an internal DNS (CoreDNS) and a network proxy to automatically route traffic to the correct container, regardless of the host machine or changing backend IPs.
The Kamal Problem: Kamal treats every VPS as an isolated island. Its built-in proxy (kamal-proxy) handles local Blue-Green transitions excellently on a single host, but it knows absolutely nothing about inter-machine networking.
If you spread microservices across different VPS nodes, you instantly hit two major roadblocks:
-
Egress Costs and Latency: Routing traffic between Service A and Service B via public IPs or an external public Load Balancer forces data onto the public internet. This introduces a pointless 10 - 15ms latency penalty and inflates the cloud bill via data egress charges.
-
Ephemeral IPs via Terraform: If Terraform needs to recreate a VPS instance (e.g., for a hardware upgrade), the cloud provider assigns a new private IP. Hardcoding these static IPs into Kamal's
deploy.ymlwould mean manual configuration changes on every infrastructure shift.
Our Solution: Abstraction via Private Cloud DNS
Instead of introducing a heavy service mesh (like Consul), we solved this elegantly inside the VPC (Virtual Private Cloud) using private DNS zones managed by the cloud provider and
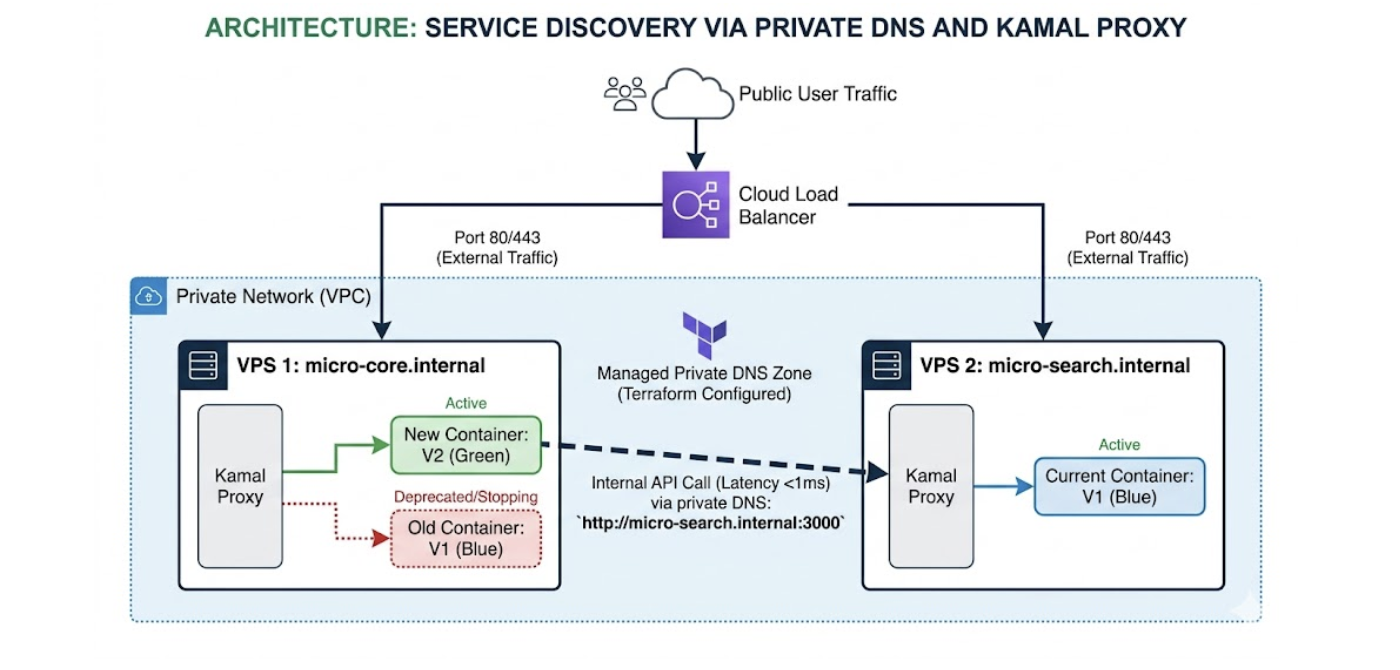
Through this approach, the Core microservice calls the search service via the internal URL http://micro-search.internal:3000. When Terraform modifies or recreates the Search VPS instance, it automatically updates the private VPC DNS record. Kamal's configuration files remain completely static and clean, and inter-service traffic never leaves the private local network (latency <1ms, zero egress costs).
A Note on Scaling & Future-Proofing: We are fully aware of the architectural runway here. At a larger scale, relying purely on Private DNS has its limits—mainly because some application-level HTTP clients aggressively cache DNS records (ignoring low TTLs), and DNS alone doesn't handle horizontal load balancing across multiple instances of the same microservice.
As traffic grows and we need to scale horizontally, our next logical step will be transitioning from Private DNS to Internal Load Balancers (ILBs). This will eliminate any DNS caching edge cases and distribute traffic seamlessly. But for our current MVP phase? This private DNS setup is absolutely unbeatable in both cost and structural simplicity.
The Execution: Surgical Blue-Green on Every Host
With private networking secured, we let kamal-proxy do what it does best: local, host-isolated Blue-Green deployments per microservice.
When our Cloud Build pipeline pushes an update strictly for the Core service, Kamal SSHs exclusively into VPS 1. The deployment algorithm runs locally:
- It pulls the new Docker image.
- It starts the new container (Green version) on an alternate port.
- It waits for the application's
/healthendpoint to return200 OK. We configured the application to only respond after the internal framework warms up and establishes managed database connections. kamal-proxyinstantly switches the local traffic flow from the old container to the new one.- The old container (Blue version) is safely stopped.
During this entire process, VPS 2 (the Search service) remains completely untouched. We achieved granular deployments without recycling or impacting the rest of the ecosystem.
What if a subtle bug slipped through testing into production? Rollback was a matter of seconds. We eliminated the need to retain latent containers on the server. Instead, rollback logic lived entirely in our CI/CD pipeline (GitHub Actions). Triggering the workflow for the previous version forced Kamal to re-execute the deployment with the prior stable image, restoring order in seconds. Because the stateful data lived in an external managed database, application state was never jeopardized.
The Part-Time Site Manager: Limitations and Bootstrapped Solutions
Let's be realistic: Kamal is not an active orchestrator. While Kubernetes is a permanent control plane constantly monitoring cluster health, Kamal acts more like a part-time site manager or a conductor who merely starts the piece. It executes instructions over SSH, ensures the proxy hooks onto the containers, and leaves.
To build an enterprise-ready system, we configured Docker and external monitoring to offset Kamal's lack of active management:
1. Process-Level Self-Healing
Kamal lacks intelligent pod rescheduling if a node suffers a hardware failure (if the VPS dies, the app goes down until manual intervention). However, at the process level, Kamal natively injects Docker's restart: always policy. If a microservice suffered an internal crash at 3 AM, the local Docker daemon restarted it instantly without requiring Kamal's intervention.
2. Unified Observability: Promtail + Loki + Grafana
To avoid running two massive monitoring stacks on a tight budget, we unified logs and metrics using the Grafana ecosystem. Promtail runs as a lightweight daemon on each VPS, scraping logs directly from the Docker socket and shipping them to Loki.
Through LogQL queries, we transformed text logs into real-time metrics (e.g., counting 5xx errors or measuring response latencies). Grafana alerts notified us instantly via chat channels if an instance became unreachable, filling the gap left by a cluster manager.
3. Avoiding Noisy Neighbors (Resource Limits)
In a lean infrastructure, a memory leak in one microservice can choke the entire host. While K8s forces resource boundaries by design, Kamal requires you to pass them explicitly as Docker options in deploy.yml to safeguard the host machine:
YAML
options:
max_memory: "512m"
max_cpus: "0.5"Conclusion
Our pilot project proved that you don't need an architectural monolith like Kubernetes to achieve a modern, secure, and isolated delivery pipeline.
By abstracting Service Discovery into the cloud provider's private DNS network and leveraging kamal-proxy intelligently, we achieved a per-microservice Blue-Green pipeline at a microscopic fraction of standard cloud costs. Kamal won't hold your hand, but when paired with solid networking practices and robust monitoring via GitHub Actions and Grafana, it becomes an unbeatable tool for pragmatic engineering teams.
LATEST LABS
The Kubernetes Tax: How We Achieved Per-Microservice Blue-Green Deployments Using Kamal Deploying HelixML on Talos: from kernel ABI quirks to a working coding-agent fleet Deploying OpenEBS Mayastor on Talos Linux: A Production Guide The True Cost of the Post-NAB Roadmap: Scaling Specialized Engineering GitOps Secret Management with HashiCorp Vault, ESO, and ArgoCD See AllLABS CATEGORIES
 News
Lab Projects
Article
News
Lab Projects
Article